
RAG, CAG & Fine-tuning, implementaciones de IA en local
La idea es simple: no todas las empresas quieren usar la IA “tal cual viene” de fábrica, sino que necesitan adaptarla con sus propios datos, su propio lenguaje y su propio contexto, y al mismo tiempo hacerlo de forma segura y privada.
Actualmente existen 3 formas principales de “personalizar” una inteligencia artificial para que se adapte a las necesidades de una empresa.
- CAG: ideal para acelerar respuestas repetidas.
- RAG: perfecto para consultar la información de tu empresa en tiempo real y sobre miles de documentos.
- Fine-tuning: la IA aprende a trabajar exactamente como tu empresa necesita.
CAG (Cache-Augmented Generation)
Imagina que vas hablando con tu amigo/a en una cafetería, y os pasáis varias horas hablando de diferentes temas. Ahora, cuando le vuelves a hablar sobre el primer tema de la conversación, es posible que no se acuerde muy bien de qué es de lo que estabais hablando al principio, esta memoria sobre la conversación en IA se conoce como el CONTEXTO de la conversación y tiene impacto en el CAG.
Con CAG, las respuestas más usadas o más frecuentes se guardan en una caché (una especie de memoria rápida, como la RAM). Así, la próxima vez que alguien pregunte lo mismo, la IA responde mucho más rápido y sin tener que “pensar tanto”. Pero cada IA tiene un tamaño para el contexto donde se permite guardar toda esa información de la conversación, si ese contexto se llena, lógicamente irá vaciando lo más antiguo y guardando lo más nuevo, eso hay que tenerlo en cuenta por muy grande que sea el contexto.
Aún así, el CAG nos permite ahorrar en recursos, costes y tiempo, garantizar respuestas más consistentes y es muy útil para las preguntas de los usuarios que más repiten. Ejemplos: ¿Cómo doy de alta un cliente?¿Cómo registro un clientes en mi ERP?¿cuál es el número del jefe del departamento de ventas?
Estás preguntas se repetirían por nuevas incorporaciones del equipo de ventas, y ya no habría una persona encargada de formar a esta nueva incorporación, en efecto, ahorra en recursos, costes y tiempo.
¿Cómo se consigue implementar el CAG en una IA en local?
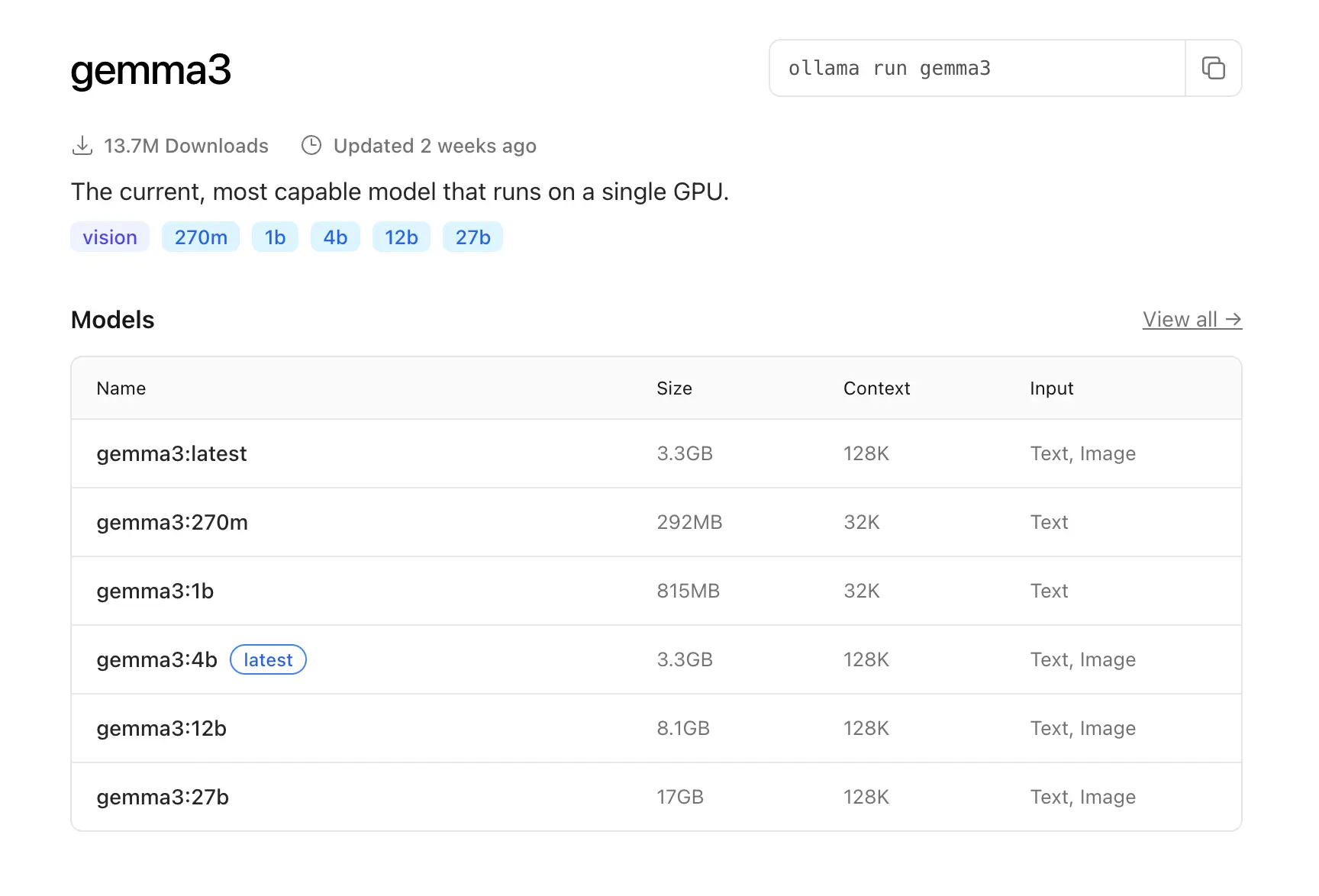
En un modelo de IA local, el modelo que elijamos, tendrá un CONTEXTO, esto es la capacidad de la IA de almacenar información en caché. Es decir, a modo de ejemplo en la imagen de abajo
 31 agosto 2025 | fuente
31 agosto 2025 | fuente
vemos que en ollama nos deja elegir varios modelos de gemma3, el size y los números al lado del nombre, “gemma3:1b” o “gemma3:4b” se trata de la cantidad de datos con los que se ha entrenado el modelo, teóricamente cuanto más azúcar más dulce, luego, fijémonos en el Context, este es la ventana que tenemos para el CAG.
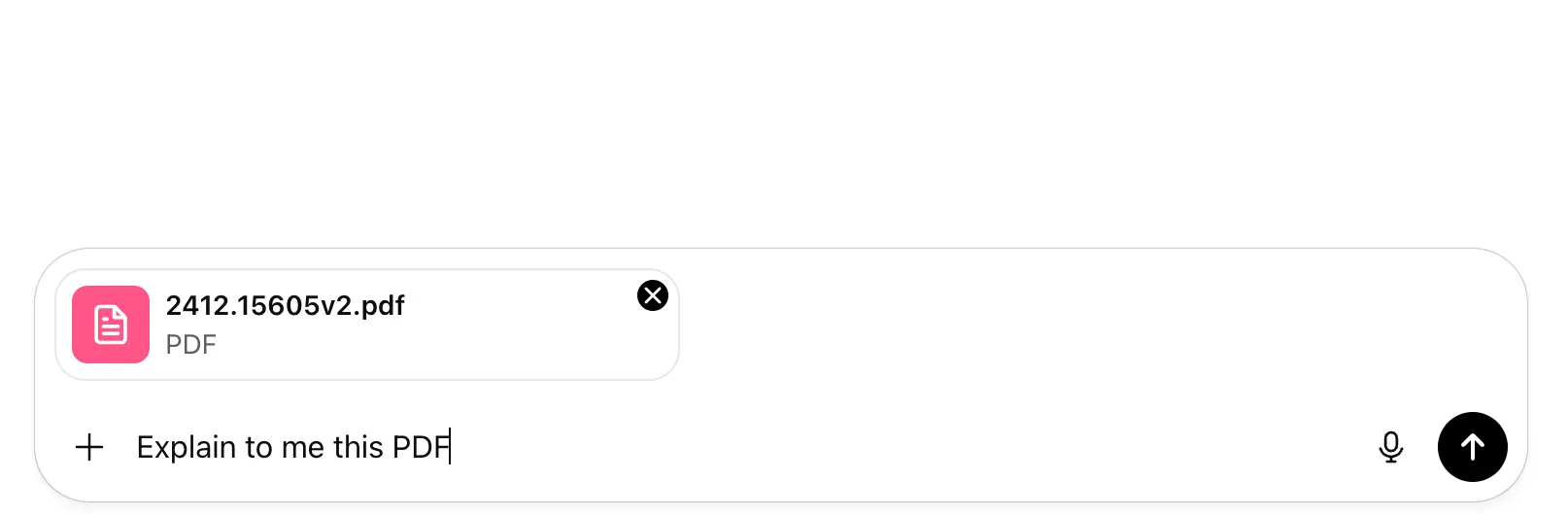
De una forma más sencilla, en la imagen de abajo vemos como le pasamos un PDF que contiene varias palabras e imágenes, que serán representados en tokens, si el pdf no excede el límite de los tokens podrá basarse en la información del pdf, pero, según “hablamos” con la IA del pdf, este va a ir olvidándose del contenido del PDF.
 31 agosto 2025 | fuente
31 agosto 2025 | fuente
A mi me gusta pensar que es la forma rápida de consumir información específica de una fuente de datos, un documento, una página web, una sentencia. Digamos que no es lo ideal para una compañía que tiene centenares o miles de documentos cambiantes y grandes cantidades de información y procesos que los usuarios consultan a menudo.
Para ello lo ideal sería utilizar RAG.
RAG (Retrieval-Augmented Generation)
Imagina que la IA es un estudiante muy listo, pero que no se sabe de memoria tus manuales, contratos o documentos internos. Por ejemplo, en CAG, cabrían ciertos documentos o cierta información, PERO, no cabrían todos si son decenas, centenas o miles de documentos de varias páginas para los procesos de una empresa.
Con RAG lo que haces es darle acceso a una biblioteca privada de documentos, cada vez que le haces una pregunta la IA busca la información relevante en esa biblioteca y después genera la respuesta.
De esta forma, no se modifica la IA original, se conecta a tus datos cada vez que respondes y además es un método ideal si la información cambia a menudo ya que no perdería la memoria.
Ejemplo: un asistente que responde dudas sobre tu catálogo de productos sin necesidad de entrenarlo desde cero.
¿Cómo se consigue implementar el RAG en una IA en local?
Aquí la cosa se complica, no es tan sencillo como en CAG que eliges un modelo con un contexto enorme y prácticamente ya estarías listo, acuérdate que lo único malo es que va “perdiendo la memoria” según avancen las consultas. Pero con RAG, como hemos mencionado antes, esto no pasa.
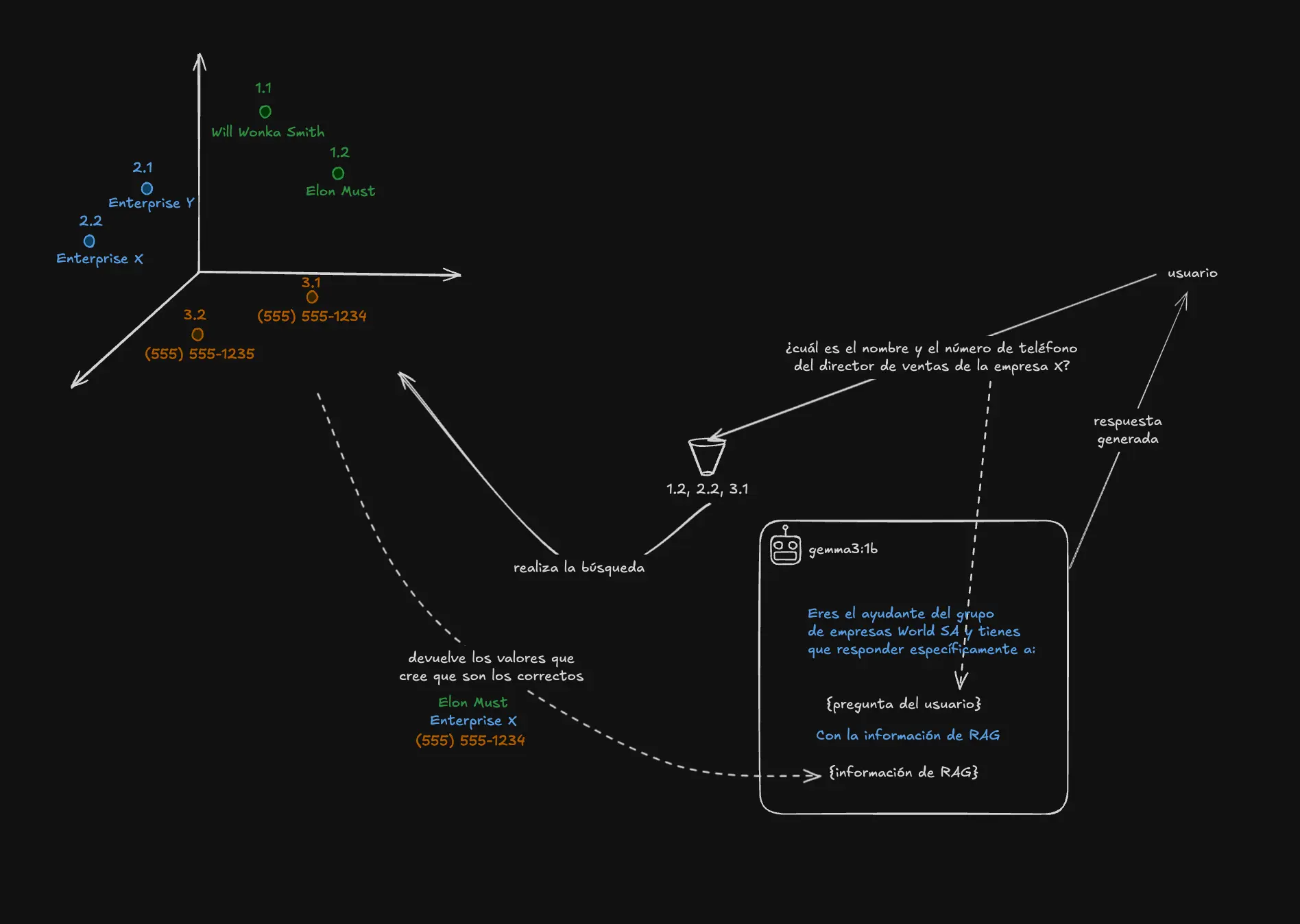
Lo primero que pasa en RAG cuando preguntamos por ejemplo: ¿cuál es el nombre y el número de teléfono del director de ventas de la empresa X? (imagina que formas partes de un grupo de empresas) es que pasa por un, digamos embudo o codificador, este lo único que hace es convertir la consulta del usuario en valores numéricos para poder utilizarlos en una base de datos vectorial y poder entender qué información busca el usuario y devolverle la información es específico que busca el usuario.
Pero claro, antes, tenemos que haber procesado esa información, es decir, la información del grupo de empresas y de los nombres de los empleados y directores junto con su número de teléfono, habrán pasado por ese embudo o codificador para poder representar y guardar la información en la base de datos vectorial.
El segundo paso sería que el propio codificador va a consultar en la base de datos vectorial los datos más relevantes.
 31 agosto 2025 | fuente propia
31 agosto 2025 | fuente propia
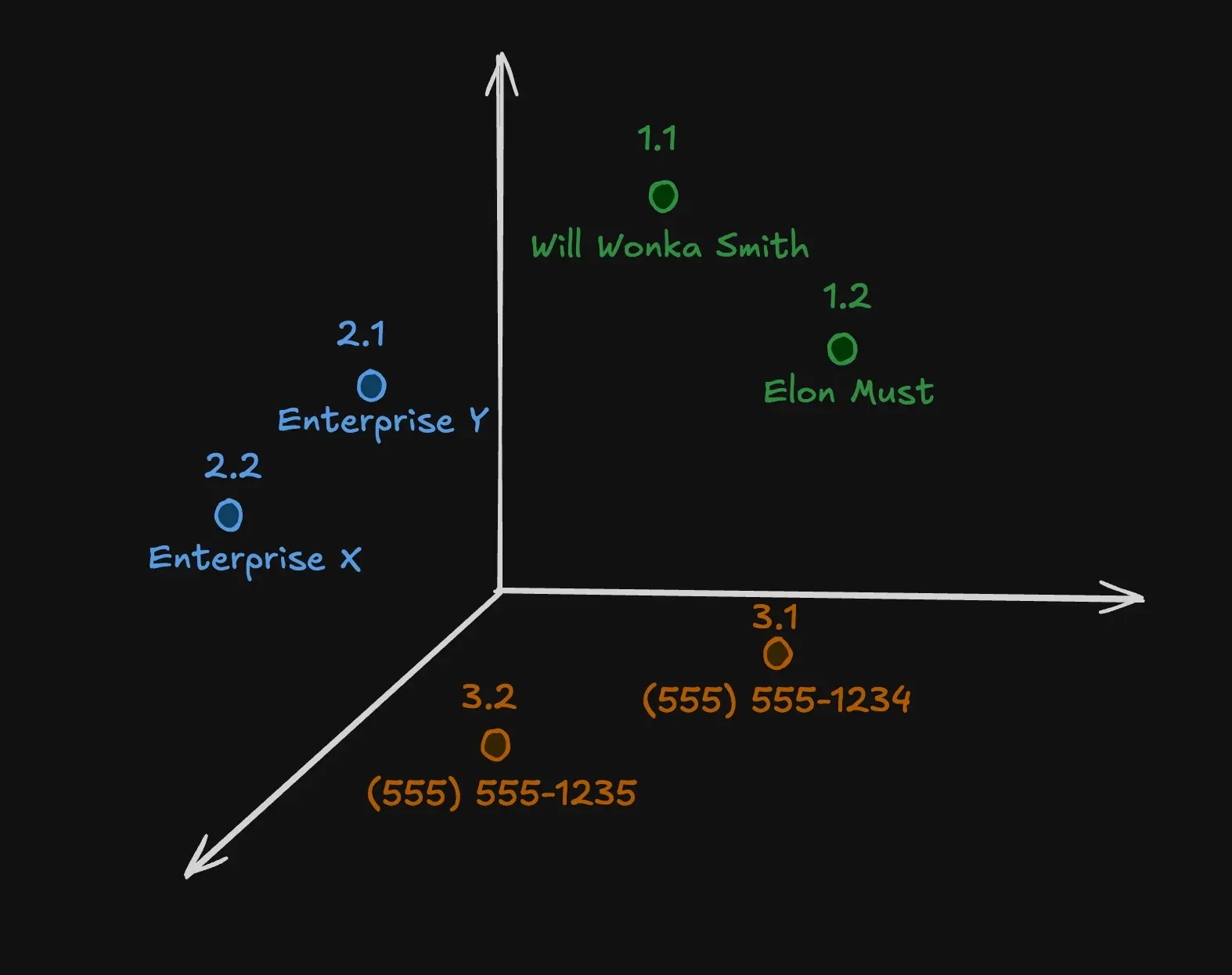
En la representación de la imagen de la base de datos vectorial vemos como habrían nombres, empresas y teléfonos, claro, estos tendrán relaciones, es decir, va a buscar el nombre del director comercial y el número de teléfono de ese director comercial, digamos que perfectamente podría devolver algo como:
“Nombre: Elon Must, Empresa: Enterprise X, Número de teléfono: (555) 555-1234.” y esto se lo pasará a la IA generativa, para posteriormente contestarnos a nosotros.
 31 agosto 2025 | fuente propia
31 agosto 2025 | fuente propia
En la imagen superior vemos que a la IA generativa, le pasamos una especie de información de cómo debe actuar y/o contestar, además de la pregunta original del usuario junto con la información de la base de datos vectorial.
El sistema de RAG también puede llegar a ser complejo sobre la cantidad de datos y relaciones que puedan llegar a tener, la imagen de abajo es un ejemplo de representación sobre una base de datos vectorial donde cada punto representa un artículo, y su color representa su tema en un modelo jerárquico de temas.
 31 agosto 2025 | fuente
31 agosto 2025 | fuente
Fine-tuning
Aquí sí vamos un paso más allá ya que el Fine-tuning consiste en ENTRENAR el modelo de IA con tus propios ejemplos para que “aprenda” a responder como tú quieres. No solo consulta tus datos, sino que se adapta a tu estilo, tu vocabulario y tu forma de trabajar.
Este proceso es más complejo, para lograrlo lo primero que necesitamos son muchos datos de nuestra empresa, de preguntas y respuestas para poder entrenar al modelo en base a nuestros datos.
Los pasos serían:
-
Recolectar datos
- Necesitas muchos ejemplos de preguntas y respuestas reales de tu empresa.
- Cuantos más y mejor organizados, más aprenderá el modelo.
- Ejemplo: “¿Cómo crear una factura?” → “Entra en el ERP, menú Finanzas, opción Facturas, botón Crear”.
-
Preparar el dataset
- Los datos deben estar en un formato entendible para el modelo (JSON, CSV o texto estructurado).
- Se suelen dividir en pares de prompt → respuesta.
- También se limpian duplicados y se corrigen errores.
-
Elegir el modelo base
- Puede ser un modelo abierto (ej. LLama, Mistral, Falcon) o uno privado.
- La clave es que soporte fine-tuning.
-
Entrenar (fine-tuning)
- Se pasan tus datos al modelo en un proceso de entrenamiento.
- Aquí el modelo ajusta sus “pesos internos” para parecerse a tu forma de contestar.
- Necesita potencia de cómputo (GPUs/TPUs).
-
Validar y probar
- Se hacen preguntas nuevas (no vistas en el entrenamiento) para ver si responde bien.
- Si falla, se añaden más ejemplos y se repite.
-
Desplegar el modelo
- El modelo ya entrenado se guarda y se usa dentro de tu sistema (intranet, app, chatbot).
- A partir de aquí, cada respuesta seguirá el estilo y el conocimiento de tu empresa.
Conclusión
Cada enfoque tiene sus ventajas, y lo importante es elegir el que mejor se adapte a tus objetivos, siempre con la tranquilidad de que puedes hacerlo de forma privada y segura dentro de tu propia infraestructura. Desplegar un modelo privado de IA para una empresa es una tarea a tener en cuenta, ya que puede significar un avance muy rápido a nivel de productividad.
Para cualquier consulta sobre esto, dejo mi email stemitomy@gmail.com.